


ReSearch: Advancing LLM Reasoning with Reinforcement Learning and Search Integration
Explore ReSearch: A groundbreaking AI framework integrating reasoning with search in LLMs via reinforcement learning for multi-hop tasks.

Ever wondered how AI could solve complex reasoning problems while also searching for relevant information? That’s where ReSearch comes in—a smart framework that combines reasoning with search operations for large language models (LLMs), all powered by reinforcement learning.
Challenges in Multi-Hop Reasoning
Let’s start with the problem. Multi-hop reasoning involves answering questions that require multiple steps to connect facts and retrieve data. It’s like solving a puzzle piece by piece. Current methods often rely on fixed prompts or manual rules, which limits their flexibility. Plus, training AI on multi-step reasoning data takes time and money—lots of it.
ReSearch Framework Methodology
Here’s the cool part. ReSearch doesn’t depend on supervised training for reasoning steps. Instead, it introduces reasoning tags like <think>, <search>, <result>, and <answer> directly into the reasoning chain. These tags act like instructions for the AI, helping it communicate with external search systems.
The framework uses Group Relative Policy Optimization (GRPO), a reinforcement learning approach that teaches the model when to perform a search and how to use the results to refine its reasoning.
Check out Figure 1 below to see how the tags work in action.

Use Case Diagram for ReSearch Framework
This diagram shows how the LLM interacts with external search environments for reasoning and search operations.
Experimental Evaluation
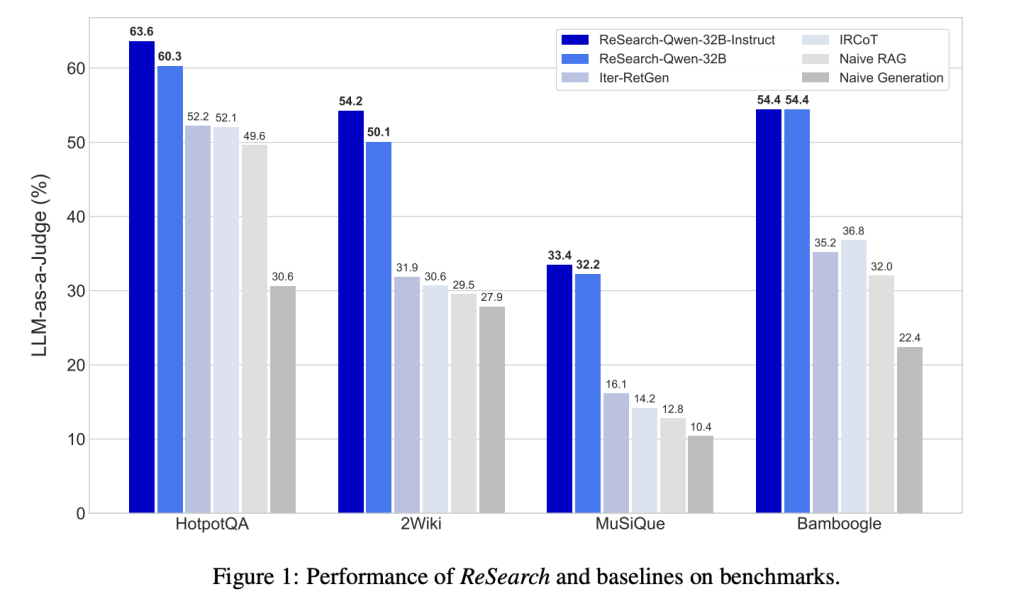
ReSearch isn’t just theory—it’s been tested. On benchmarks like HotpotQA and MuSiQue, ReSearch outperformed other methods by up to 22%! This is impressive because it only trained on a single dataset. Models even got better at iterative search, showing more advanced reasoning skills over time.
Take a look at Figure 2 below to see the benchmark results.
System Architecture Diagram for ReSearch Framework
This diagram maps the ReSearch framework components, showing the flow of reasoning tags, search queries, and results.
Future Directions
What’s next for ReSearch? Expanding to new applications and datasets could make it even more robust. Imagine AI models that use external knowledge from diverse sources, improving everything from customer service bots to medical diagnosis assistants.
Conclusion
ReSearch is a game-changer. By combining reasoning with search using reinforcement learning, it overcomes the limitations of supervised data. Its ability to adapt, reflect, and self-correct makes it a promising tool for solving complex reasoning tasks. Ready to dive deeper? Check out the research paper and GitHub repository.
FAQs
What is the ReSearch framework?
ReSearch is an AI framework that trains large language models to combine reasoning chains with search operations using reinforcement learning.
How does ReSearch integrate reasoning with search?
It embeds reasoning tags like <think> and <search> into the output, guiding the model to interact with external search systems.
What is Group Relative Policy Optimization (GRPO)?
GRPO is a reinforcement learning technique that helps the model decide optimal moments for search operations.
How does ReSearch improve multi-hop reasoning?
By enabling iterative search and reasoning steps, ReSearch refines answers automatically without needing supervised data.
What benchmarks were used to evaluate ReSearch?
ReSearch was tested on HotpotQA, MuSiQue, and other multi-hop reasoning benchmarks, showing significant performance improvements.


